
数据解读:国内最大设计论坛站酷首页

站酷是国内最大的设计设计师交流论坛,涵盖各类设计以及纯艺术。我爬取了站酷首页1-100页的数据(因为站酷首页100页以后网站不保存了拿不到数据)。
我在当设计师的时候就对站酷很好奇,究竟是什么作品能够更受站酷小编的青睐。设计师更喜欢点赞评论什么作品?又是什么人是常年霸占首页大屏的呢?
文章最后放上代码
什么作品类型在首页推荐里面出现最多?
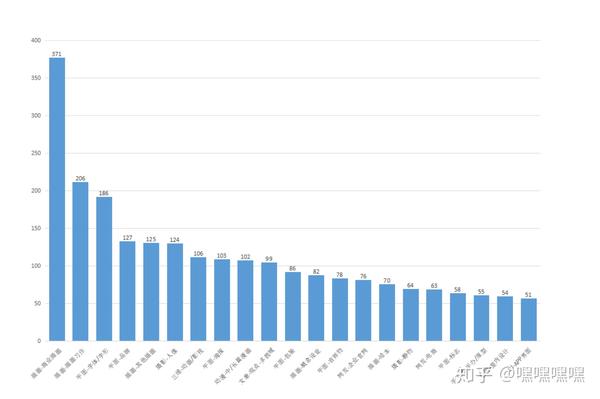

以上列出了排名前20的数据,原本以为红的发紫的C4D类的三维会占据首页,没想到插画类的才更受站酷小编青睐。商业插画占了整个首页所有3974个作品的9.5%。商业插画是插画的子类,而整个插画的大类在排名前20的作品类别中占据了5个。


以大类来分类也明显看出插画以及平面是所有大类的大头,两者的数量相加等于整个站酷所有首页作品数量的43%左右。
根据我个人理解,插画更适合高端定制,主题分明,个人习作也是有相当大的辨识度,但是插画这个不是一时半会能练出来的因此会的人特别少,而想要插画风格的大客户也特别多。我认为高端定制的插画将来会是一个无法替代的工作,资源都会被插画大佬给包揽。虽然说目前平面工作确实苦逼,钱少事多。但也是特别体现设计师综合能力的,囊括了三维,插画,拍摄各行各业,随便一块都够吃一壶的了。我个人而言也更愿意欣赏平面的大佬。
那小编喜欢插画和平面,其他设计师喜欢吗?
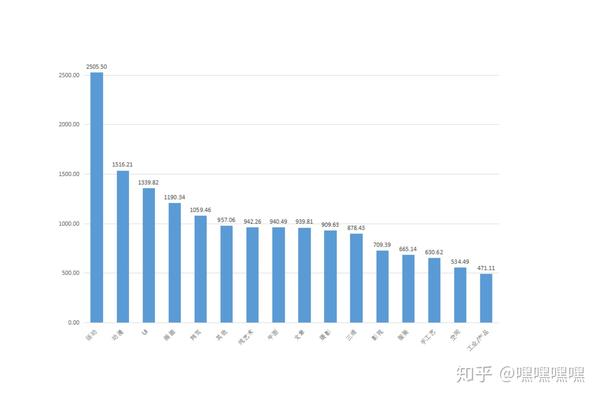



对站酷所有大类的点赞做了一个汇总,最高点赞和评论的是站酷的活动专题汇总。看来站酷里面热爱学习和练习的人还是特别多的。站酷也有很多设计师讨论的活动专题,由此也间接的看出站酷确实是一个相当热闹的设计师交流平台。
那么去掉站酷活动,其余大类的排名分别是:




UI设计虽然呈现明显的下滑趋势,慢慢的往动效方向转变。但惊奇的发现UI作品在评论和点赞数都位于各大设计行业的前2。我认为这个也是和做的人基数大有关。但是为什么首页UI相关的作品根本排不上名次呢?我认为可能也是学的人多但精的不多,真正牛逼的人可能也是那么几个。
点赞数量和作品上首页的时间有没有什么关系呢?点赞数量的分布是怎样呢?
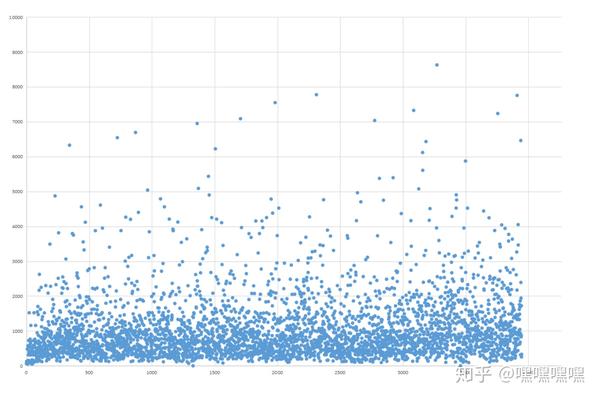

图片横轴为上首页的时间顺序,纵轴为点赞数,由图片看来是不太大的。但是也分析出了一个结论:点赞数量扎堆在1000以下,2000以上的明显就稀疏多了。
最受欢迎的设计师是谁?
除去2个站酷官方账号。以下为上首页次数前8设计师名单:
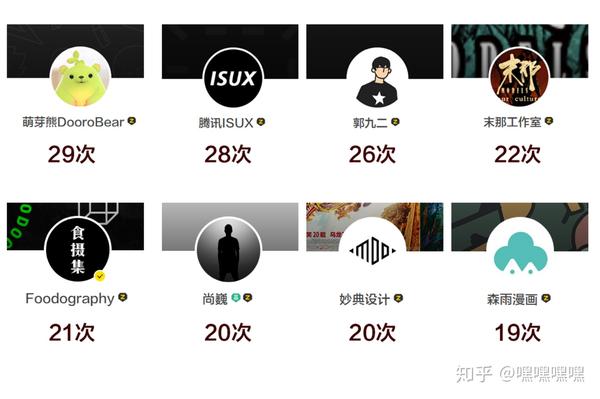

我进他们的首页观察了一下,上榜的设计师除了腾讯的官方号均有明显的个人风格,一看小图就知道作者是谁。其中贡献最大的当然是尚魏啦,曾经一直用他的毛笔字体。
点赞数量最高的4个作品分别是:


喵呜不停的站酷值得爱猫的同学们关注,真的是萌化了。
他的主页: https://idudu.zcool.com.cn/
左手韩以前上班摸鱼的时候也特别爱看他的漫画,夸张的画风诙谐的内容。也是能时不时的戳到笑点。
最后:
由于站酷首页推荐只有100页,所以更远古的数据拿不到了。否则可以进而分析设计的趋势,还有站酷的历史
那么本次对于站酷首页的数据分析就到这里了。总结了以下几点:
- 常上首页的设计师们大多是有着明显的个人风格。
- 人们更偏向于看插画和漫画,更偏向于点赞和评论UI。
- 平面作品上首页比我想象中的多,而目前大红的三维动效比我想象中的少。
最后是这次抓取站酷首页的代码:
import requests
from lxml import etree
import html
import re
import time
domain='https://www.zcool.com.cn'
baseurl="/?p={}#tab_anchor"
patten=re.compile('<.*?>')
def getpagenum(a):
url=domain+baseurl.format(a)
res=requests.get(url)
time.sleep(4)
return res.text
def gerpage(c):
tree = etree.HTML(c)
table_row = tree.xpath('//div[@class="card-box"]')
boards = []
for row in table_row:
board = {}
try:
board['类别'] = row.xpath('div[@class="card-info"]/p[@class="card-info-type"]')[0].text
board['点赞'] = row.xpath('div[2]/p[3]/span[3]')[0].text
name2=row.xpath('div[3]/span[1]/a')[0]
name2 = etree.tostring(name2).decode('utf-8')
name2 = html.unescape(name2)
name2 = patten.sub('', name2)
name2=name2.strip()
board['评论']=row.xpath('div[2]/p[3]/span[2]')[0].text
board['作者'] = name2
except Exception as err:
#print('error:',err)
pass
boards.append(board)
return boards
def main():
n=[]
for i in range(0,99):
c=getpagenum(i)
page=gerpage(c)
n.append(page)
print(n)
if __name__ == '__main__':
main()